Non serve che sia io a spiegarvi quanto i modelli di intelligenza artificiale abbiano e stiano tuttora permeando ogni aspetto della nostra vita: dal celeberrimo Chat-GPT® alla funzione di dettatura automatica di Word® passando per il generatore di immagini Dall-E® arrivando al sistema di riconoscimento facciale che ci permette di sbloccare il nostro smartphone.
Sono quasi certo che la maggior parte di voi si trovi a fruire di queste tecnologie stupendosi di quanto siano efficaci senza essere in grado di comprenderne la natura, dandosi come unica e sufficiente spiegazione l’esistenza di qualche miracoloso algoritmo dietro le quinte.
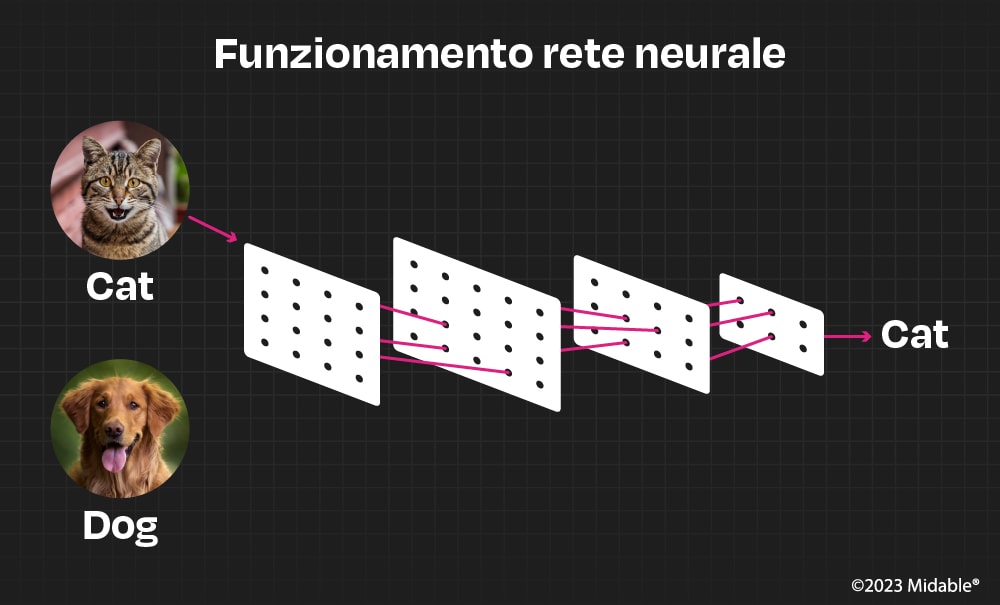
Questo articolo nasce con l’intenzione di provare a rendere più chiaro il funzionamento di questi modelli ipotizzando di voler creare un modello di intelligenza artificiale in grado di distinguere la foto di un cane da quella di un gatto.
Reti Neurali
Tutte le applicazioni sopra citate si basano sull’implementazione di modelli chiamati reti neurali.
Quando nello scorso secolo i primi ricercatori si interrogavano su come rendere i computer ”intelligenti” non sapevano come poter indurre i computer a ragionare e apprendere. Il primo tentativo fu fatto imitando quello che era stato il modello dominante fino a quel momento: il cervello umano.
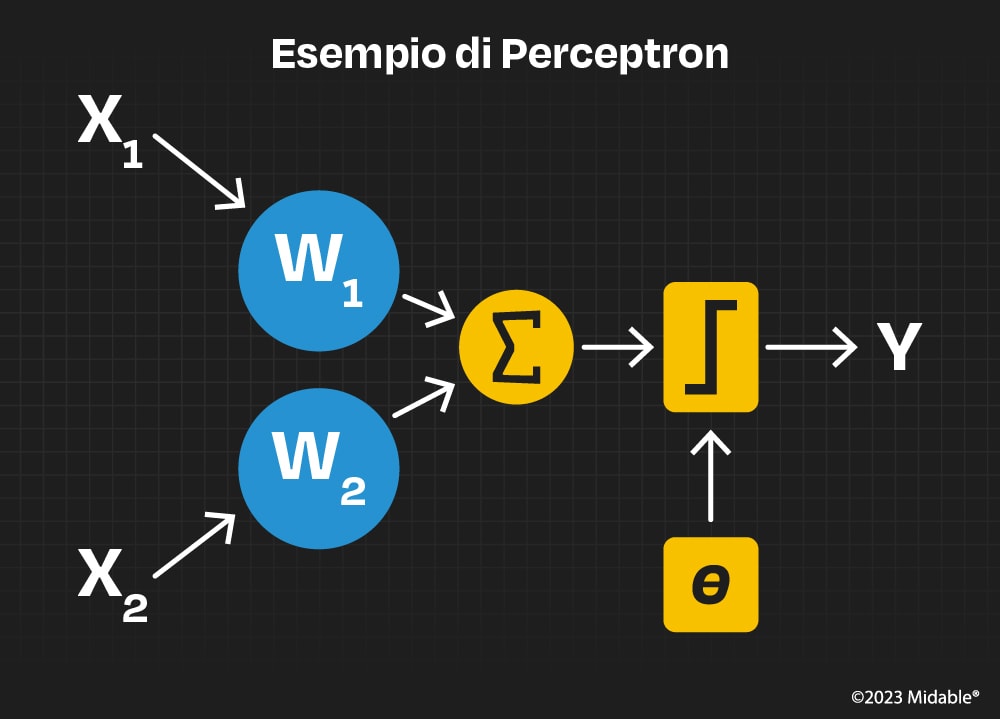
Come saprete, nel cervello umano si trovano miliardi di neuroni che si scambiano impulsi elettrici l’un l’altro mediante le sinapsi che portano ad eccitare o inibire i neuroni vicini: fu deciso di implementare degli applicativi che simulassero questo fenomeno costruendo una rete di neuroni artificiali.Nacque così, nel 1958, il primo modello di neurone artificiale che prese il nome di Perceptron. Il suo funzionamento è molto semplice: riceve in ingresso una serie di input numerici, ne esegue una somma pesata (tenete a mente questo concetto) e poi verifica che il risultato ottenuto superi un valore di soglia preimpostato; in caso affermativo darà in output +1 altrimenti restituirà il valore −1.
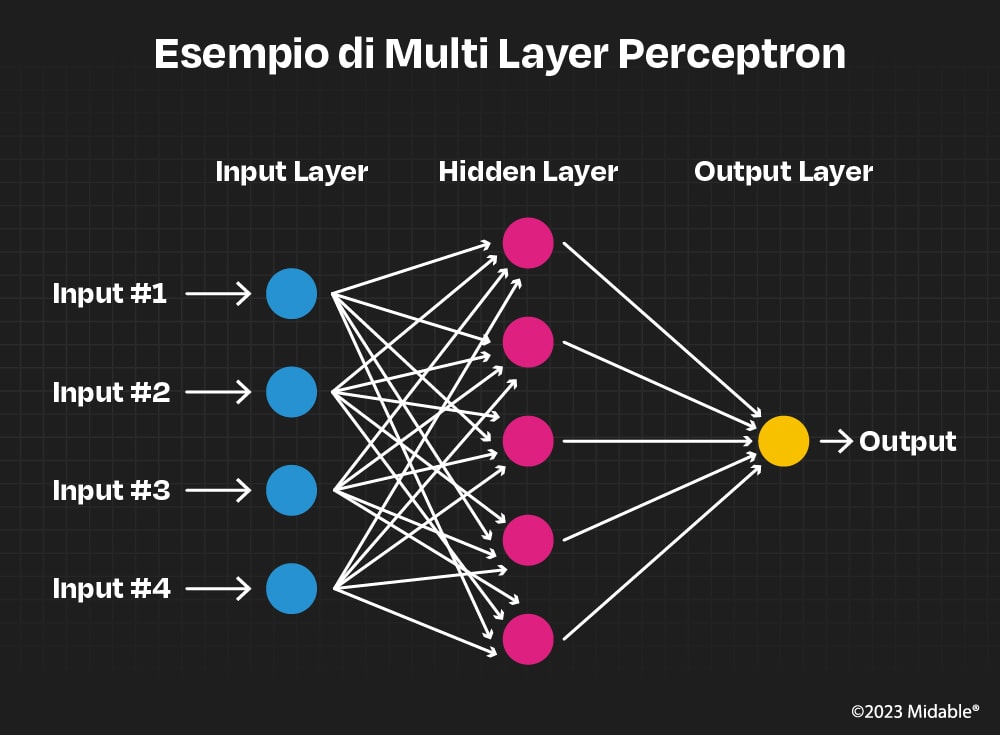
La più semplice delle reti neurali prende il nome di Multi Layer Perceptron e, come si intuisce dal nome, non è altro che una rete composta da vari Perceptron impilati su più strati dove i valori di uscita dei neuroni allo strato precedente rappresentano gli ingressi dei neuroni dello strato successivo.
Dati necessari per l’apprendimento
Adesso che abbiamo a disposizione una rete neurale dobbiamo fare in modo che quest’ultima impari a discernere tra l’immagine di un cane e quella di un gatto.
Pensate a voi stessi in prima persona, com’è che avete imparato a riconoscere un cane da un gatto? Nel corso della vostra infanzia, quando incontravate un esemplare, gli adulti intorno a voi vi suggerivano se l’animale in questione fosse un cane oppure un gatto. Reiterando questo semplice processo avete dedotto e definito una serie di vostre regole interne che vi permettono adesso di distinguere senza problemi le due specie. Non c’è stato bisogno che vi spiegassero che in media i gatti siano più piccoli dei cani, che i primi abbiano i baffi più lunghi o che i secondi siano generalmente più pelosi.
È a questo meccanismo che si ispira il processo di addestramento supervisionato (esistono anche altri metodi ma sono meno comuni) delle reti neurali. Si dice supervisionato perché, per ogni animale sottoposto alla rete durante l’addestramento, quest’ultima conoscerà esattamente la specie a cui esso corrisponde e la utilizzerà per affinare le sue abilità.
Una volta compreso il meccanismo è il momento di recuperare la più grande quantità possibile di immagini rappresentanti cani e gatti: più immagini saranno disponibili, migliore sarà il risultato conseguito. Non è sufficiente però avere a disposizione una grande quantità di immagini per far s`ı che l’apprendimento sia efficace, è fondamentale anche la varietà delle immagini raccolte. Dovete capire che la conoscenza e le abilità della rete saranno limitate a ciò che le sarà fornito in fase di addestramento: se la rete vedrà solo cani di una razza farà sicuramente fatica a riconoscere le altre, se vedrà solo gatti seduti non distinguerà quelli sulle zampe, se vedrà solo cani sull’erba non capirà che un cane può trovarsi anche sulla neve.
Non possiamo esplicitamente descrivere ad un modello quali siano le caratteristiche che differenziano i due animali perché sarebbe un processo lunghissimo e sicuramente non andremmo a coprire tutte le casistiche: si preferisce che sia il modello a dedurre le caratteristiche che li separano mediante l’osservazione di migliaia di esemplari. Capirete quindi quanto sia importante scegliere dati giusti in modo che siano i più generali possibile e rappresentino il mondo in maniera completa, senza introdurre bias di alcun tipo.
L’insieme di dati utilizzati per l’addestramento di un modello è comunemente chiamato dataset.
Da immagini a numeri
Arrivati a questo punto disponiamo di una rete neurale e di un dataset di qualità. Come facciamo a dare in input un’immagine alla rete e come facciamo a capire se creda che si tratti di un cane o un gatto?
Facciamo riferimento all’immagine della rete precedente dove abbiamo un insieme di neuroni di input ed un solo neurone di output.
Come detto, i neuroni accettano valori numerici quindi dobbiamo convertire una foto in un insieme di valori numerici. Niente di più semplice: un’immagine è composta da migliaia di pixel ed ogni pixel ha un colore che può essere rappresentato da tre valori numerici che indicano la concentrazione dei tre colori primari che lo formano (RGB: red green blu). Possiamo suddividere l’immagine in tante regioni uguali quanti sono i neuroni in input e fornire ad ogni neurone l’insieme di valori RGB che descrivono i pixel appartenenti alla regione di immagine corrispondente.
Una volta ottenuto l’input l’informazione si propagherà come descritto in precedenza mediante una serie di somme pesate (tenetele a mente) fino a produrre il valore del neurone di output. Per il nostro caso possiamo arbitrariamente decidere che se il valore è +1 la rete dichiari la presenza di un cane nell’immagine sottoposta e con −1 indicherà la presenza di un gatto.
Imparare dai propri errori
Adesso c’è tutto l’occorrente necessario: abbiamo una rete, abbiamo dei dati e sappiamo come fornire questi dati alla rete. Non resta che rendere la rete
”intelligente”!
Quando la rete neurale sarà costruita i pesi inizialmente utilizzati dai neuroni per combinare gli input ricevuti saranno casuali e, di conseguenza, lo sarà il comportamento della rete: prima del processo di apprendimento è come se tirasse ad indovinare.
L’algoritmo iterativo che si utilizza per addestrare una rete segue questi passi:
- si mostrano alla rete tutte le immagini del dataset, una alla volta;
- per ogni immagine osservata si salva quale animale la rete crede sia presente;
- si calcola quanti animali sono stati riconosciuti in maniera errata sul totale (il nome tecnico di questo valore è detto funzione di perdita);
- tramite un calcolo matematico (si calcola il gradiente della funzione di perdita), l’algoritmo riconosce quali siano i pesi dei neuroni da essere modificati per fare in modo che all’iterazione successiva la rete riesca a riconoscere correttamente più animali di quanto non abbia fatto al passo corrente. Modificare i pesi di un neurone significa fare in modo che esso consideri in maniera differente gli input ricevuti, modificandone di conseguenza il valore di uscita. Visto che i valori di uscita di un neurone diventano gli input di quelli successivi, modificare anche solo l’uscita di un neurone modifica a cascata il comportamento dei neuroni dipendenti da quello in questione potendo anche causare un eventuale cambiamento del valore finale di uscita della rete.
Per farvi comprendere meglio, immaginate di essere un DJ che, avendo a disposizione un mixer, deve replicare esattamente un suono desiderato avendo in input un certo numero di suoni. Tutto ciò che fa è ruotare le varie rotelline al fine di emulare il più fedelmente possibile il suono obiettivo, ripetendo questo processo più e più volte fino al risultato sperato.

Fate un parallelismo tra il mixer e la rete neurale, ruotare una rotellina è l’equivalente di modulare la risposta di un certo neurone rispetto ai valori di input nella speranza che la rete riesca a riconoscere meglio i due animali.
Questo algoritmo viene eseguito varie volte andando a correggere via via gli errori di riconoscimento che la rete commette. Ad ogni passo l’obiettivo è di far s`ı che alcune immagini che erano classificate erroneamente al passo precedente siano riconosciute in modo corretto al passo successivo.
Il tutto si ripete finché non si arriva ad uno stallo ovvero quando, anche modificando impercettibilmente la risposta di qualche neurone, non si riescono a migliorare le prestazioni del modello.
Conclusioni
E così che una rete diventa intelligente: ad ogni analisi del dataset corregge` se stessa, carpendo e affinando le nozioni apprese puntando ad un’accuratezza sempre maggiore. Per chi addestra una rete è sconosciuto ciò che essa analizza in un’immagine ovvero quali dettagli siano più rilevanti o quali siano le discriminanti che essa usa per la classificazione. I modelli addestrati spesso sono, anche per chi li ha creati, delle scatole nere di cui non si riesce a spiegare esattamente il perché di tutte le scelte ma non ci si interroga troppo fintanto che si ha l’impressione che funzionino a dovere (implicando una serie infinita di controversie etiche e legali).
Una volta addestrato un’intelligenza con questo procedimento ci si auspica che questa riesca correttamente a distinguere le foto esemplari che non si trovavano nel dataset ovvero che vengono viste per la prima volta e che quindi funzioni con tutti i cani ed i gatti del mondo.